Jak naprawdę działają narzędzia AI dla prawników
Wyobraź sobie, że dostajesz świetnie napisaną opinię prawną. Język precyzyjny, struktura logiczna, wnioski brzmią przekonująco. Jest tylko jeden problem: nie widać źródeł. Nie wiesz, które tezy wynikają z przepisu, które z orzecznictwa, które z komentarza, a które są po prostu elegancko ubraną intuicją autora.
Taka opinia bywa pomocna jako szkic. Porządkuje problem, podsuwa kierunek argumentacji, pozwala szybciej zacząć pracę. Ale nie złożysz jej u klienta ani w sądzie bez sprawdzenia podstaw.
Z narzędziami AI jest podobnie — tylko że jeszcze łatwiej dać się zwieść. Tekst pojawia się natychmiast, brzmi profesjonalnie i często naprawdę jest blisko prawdy.
Prawnik, który traktuje ChatGPT jak „mądrą wyszukiwarkę", prędzej czy później powoła się na wyrok, który nie istnieje. Prawnik, który nie rozumie różnicy między czatem a agentem, nie zauważy, że ktoś inny robi w pół godziny pracę, na którą jemu schodzi pół dnia. Prawnik, który nie wie, czym jest grounding, nie potrafi ocenić, dlaczego jedno narzędzie myli się częściej niż drugie — i nie umie wybrać rozsądnie.
Ten artykuł nie ma zrobić z Ciebie inżyniera AI. Ma dać Ci mapę, która zostanie. Po lekturze będziesz rozumieć, czym naprawdę jest LLM, dlaczego potrafi halucynować, czym ChatGPT różni się od specjalistycznego narzędzia prawniczego, co to jest RAG, czym jest agent AI, jak działa agentic search — i jak korzystać z tego wszystkiego z głową w codziennej pracy.
Co to jest LLM?
LLM, czyli Large Language Model, najprościej opisać jako system trenowany do przewidywania kolejnego tokenu w kontekście.
To uproszczenie — ale bardzo użyteczne. Tłumaczy dwie rzeczy naraz: skąd bierze się imponująca płynność odpowiedzi i dlaczego płynność językowa nie jest jeszcze gwarancją prawdziwości.
Wyobraź sobie, że dajesz modelowi początek zdania:
„Sąd Najwyższy w wyroku z dnia 12 marca 2019 roku, w sprawie o sygnaturze…"
Model nie „sprawdza odpowiedzi w bazie", tak jak robi to klasyczna wyszukiwarka. Analizuje wszystko, co do tej pory zobaczył w rozmowie, i na podstawie wzorców poznanych w czasie treningu wybiera kolejne tokeny — te, które najlepiej pasują jako dalszy ciąg tekstu.
I tu uwaga: nie chodzi o pojedyncze słowo wyrwane z kontekstu. Współczesny model bierze pod uwagę całe zdanie, wcześniejsze akapity, samo pytanie, ton wypowiedzi, typ dokumentu, dziedzinę prawa, podobne konstrukcje językowe, a często też cały dotychczasowy przebieg rozmowy. Dlatego potrafi brzmieć jak prawnik, pisać uzasadnienia i składać memo, które na pierwszy rzut oka wygląda na profesjonalne.
Tylko że to, jak dobrze model przewiduje, jak powinna brzmieć odpowiedź, jeszcze nie znaczy, że każdy jej szczegół jest prawdziwy.

Tokeny: mały detal, duże znaczenie
Model nie operuje na „słowach" w potocznym sensie. Operuje na tokenach — fragmentach tekstu, które bywają całym słowem, częścią słowa, liczbą albo pojedynczym znakiem.
To ma bardzo konkretne konsekwencje. Dla modelu liczby nie są „liczbami" w sensie arytmetycznym. Sygnatura akt, data wyroku czy numer przepisu są dla niego po prostu kolejną sekwencją tokenów. Model zna ich typowy format, potrafi go odtworzyć, ale nie ma żadnej wbudowanej gwarancji, że konkretny numer odpowiada istniejącemu źródłu.
Dlatego narzędzia AI świetnie radzą sobie z redakcją, porządkowaniem myśli, streszczaniem, tłumaczeniem i proponowaniem struktury argumentacji. Dużo ostrożniej trzeba traktować je tam, gdzie pojawiają się sygnatury, daty orzeczeń, dokładne cytaty, numery Dz.U. i konkretne jednostki redakcyjne przepisów.
Halucynacje — małe ryzyko, duże konsekwencje
W maju 2023 roku adwokat Steven Schwartz z Nowego Jorku złożył w sądzie pismo, w którym powołał się na sześć orzeczeń. Wszystkie sześć — razem z sygnaturami, datami i cytatami z uzasadnień — wygenerował ChatGPT. Żadnego z tych wyroków nigdy nie było. Sąd nałożył sankcje, a sprawa Mata v. Avianca, Inc. stała się symbolicznym ostrzeżeniem dla całej branży. Skala jest większa, niż się wydaje — zebraliśmy ją w osobnym tekście: Halucynacje AI w sądzie — 1044 udokumentowane przypadki.
Najprostszy komentarz brzmi: „model zmyślił wyroki". To prawda, ale to wyjaśnienie jest zbyt płytkie.
LLM nie strzela w ciemno. Bierze pod uwagę kontekst pytania, wcześniejszą rozmowę, dziedzinę prawa, styl orzecznictwa, typową strukturę argumentacji, wzorce sygnatur i znaczeniowe powiązania między pojęciami. Im lepszy kontekst dostaje, tym częściej trafia blisko poprawnej odpowiedzi.
Właśnie dlatego modele bywają przydatne. Problem polega na czymś subtelniejszym: kontekst zwiększa trafność, ale nie zastępuje źródła.
Model potrafi trafnie rozpoznać, że pytanie dotyczy prawa zobowiązań. Potrafi poprawnie wskazać, że chodzi o odpowiedzialność kontraktową, należytą staranność albo przedawnienie. Potrafi nawet zbudować sensowną linię argumentacji. Ale w momencie, gdy schodzi na poziom konkretu — sygnatury, daty, numeru przepisu, przypisania konkretnej tezy do konkretnego wyroku — pojawia się ryzyko.
Najczęściej drobne. W prawie zwykle jednak krytyczne.

Dla czytelnika różnica między „Sąd Najwyższy wypowiadał się w podobnych sprawach" a „Sąd Najwyższy w wyroku z dnia 12 marca 2019 r., I CSK 7821/19, wskazał…" jest fundamentalna. Pierwsze to ogólna teza. Drugie udaje fakt, który ktoś może sprawdzić.
Halucynacja nie zawsze wygląda jak absurd
W pracy prawniczej halucynacja bardzo rzadko wygląda jak kompletny nonsens. Znacznie częściej wygląda jak odpowiedź, która trafnie rozpoznaje problem, dobrze brzmi, ma logiczną strukturę, używa właściwego języka — i myli się w jednym, precyzyjnym detalu.
Model potrafi podać sygnaturę bardzo podobną do prawdziwej, przypisać właściwą tezę nie temu wyrokowi, połączyć fragmenty kilku spraw w jedną nieistniejącą całość albo wskazać przepis, który istnieje, ale nie mówi dokładnie tego, co model zakłada.
Dwa typy halucynacji
Typ pierwszy: model cytuje coś, czego nie ma — nieistniejącą sygnaturę, nieistniejący wyrok, nieistniejący numer aktu. Ten błąd jest stosunkowo łatwy do wychwycenia.
Typ drugi: model cytuje coś, co istnieje, ale błędnie przypisuje treść. Sygnatura jest. Przepis jest. Data wygląda poprawnie. Tylko że źródło nie wspiera tezy, którą model na nim opiera.
Drugi typ jest groźniejszy, bo łatwiej go przeoczyć. Prawdziwe pytanie brzmi nie tylko: „czy to źródło istnieje?", ale też: „czy to źródło naprawdę mówi to, co model twierdzi?".
LLM, czat ogólny i narzędzie prawnicze — to nie są synonimy
Tu właśnie wiele osób miesza pojęcia. Prawnik mówi: „używałem AI". Tylko co dokładnie ma na myśli? Sam model językowy? Ogólny czat typu ChatGPT? Wyspecjalizowane narzędzie prawnicze? Wewnętrzny system kancelarii zintegrowany z bazą dokumentów?
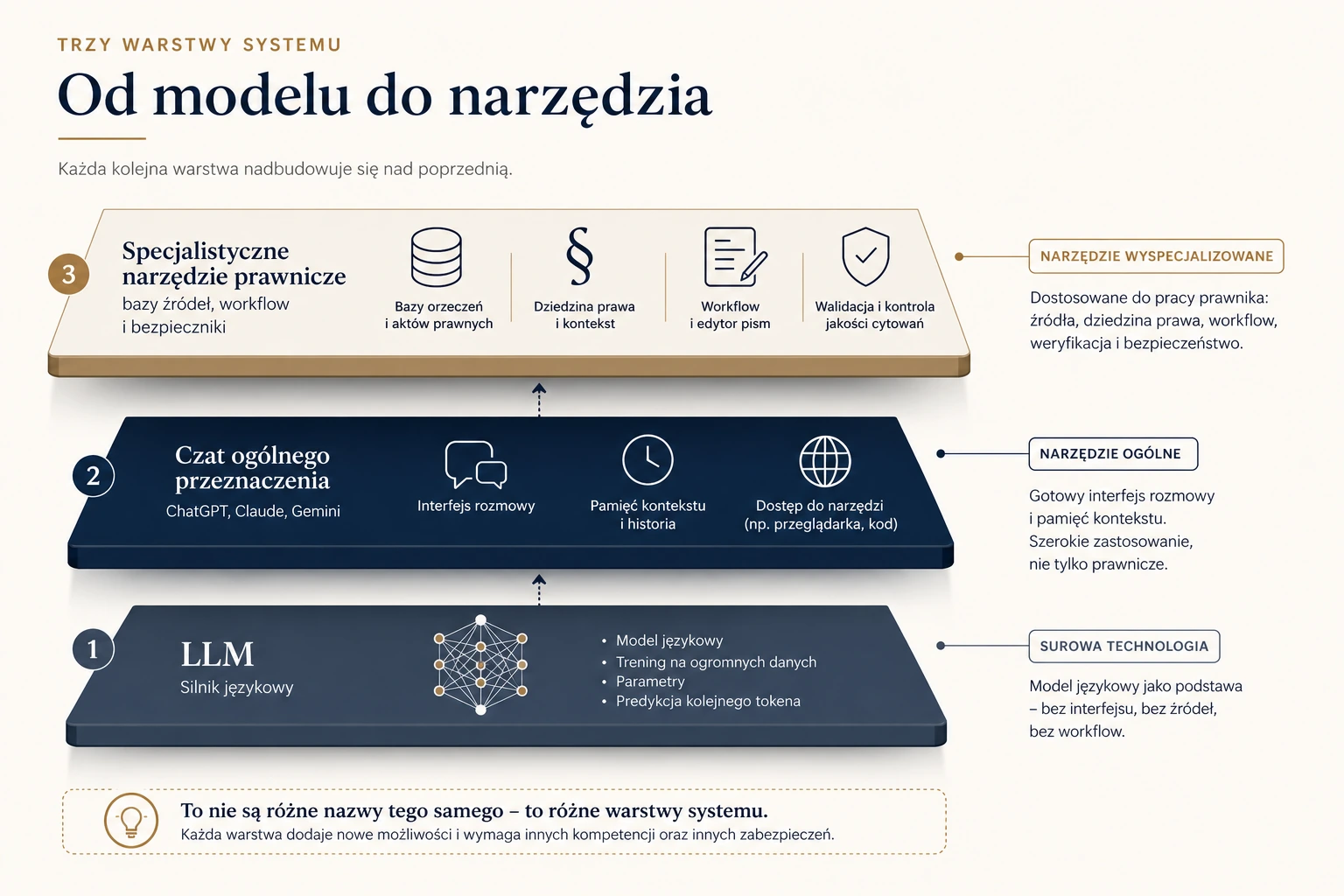
To nie są synonimy. Najuczciwiej myśleć o tym jak o trzech warstwach jednego stosu.
Najniżej leży sam LLM — technologia bazowa. Wytrenowany model, który przewiduje kolejne tokeny i nic poza tym.
Wyżej są aplikacje ogólnego przeznaczenia, takie jak ChatGPT. Dokładają interfejs rozmowy, kontekst, pamięć sesji, czasem dostęp do internetu — ale w środku nadal pracują na ogólnym modelu, bez specjalistycznej bazy źródeł.
Najwyżej są narzędzia prawnicze, które dokładają kolejną warstwę: bazy orzeczeń, bazy aktów prawnych, wersjonowanie przepisów, walidację cytowań, integrację z dokumentami kancelarii, workflow pisania pism i memo, kontrolę jakości. Jeśli chcesz przegląd konkretnych narzędzi i danych o ich skuteczności, zobacz: AI dla prawników 2026 — co naprawdę działa.
RAG — daj modelowi otwartą książkę
Wiemy już, że model bez dostępu do źródeł generuje tekst przekonujący, ale niekoniecznie zweryfikowany. Jak to ograniczyć?
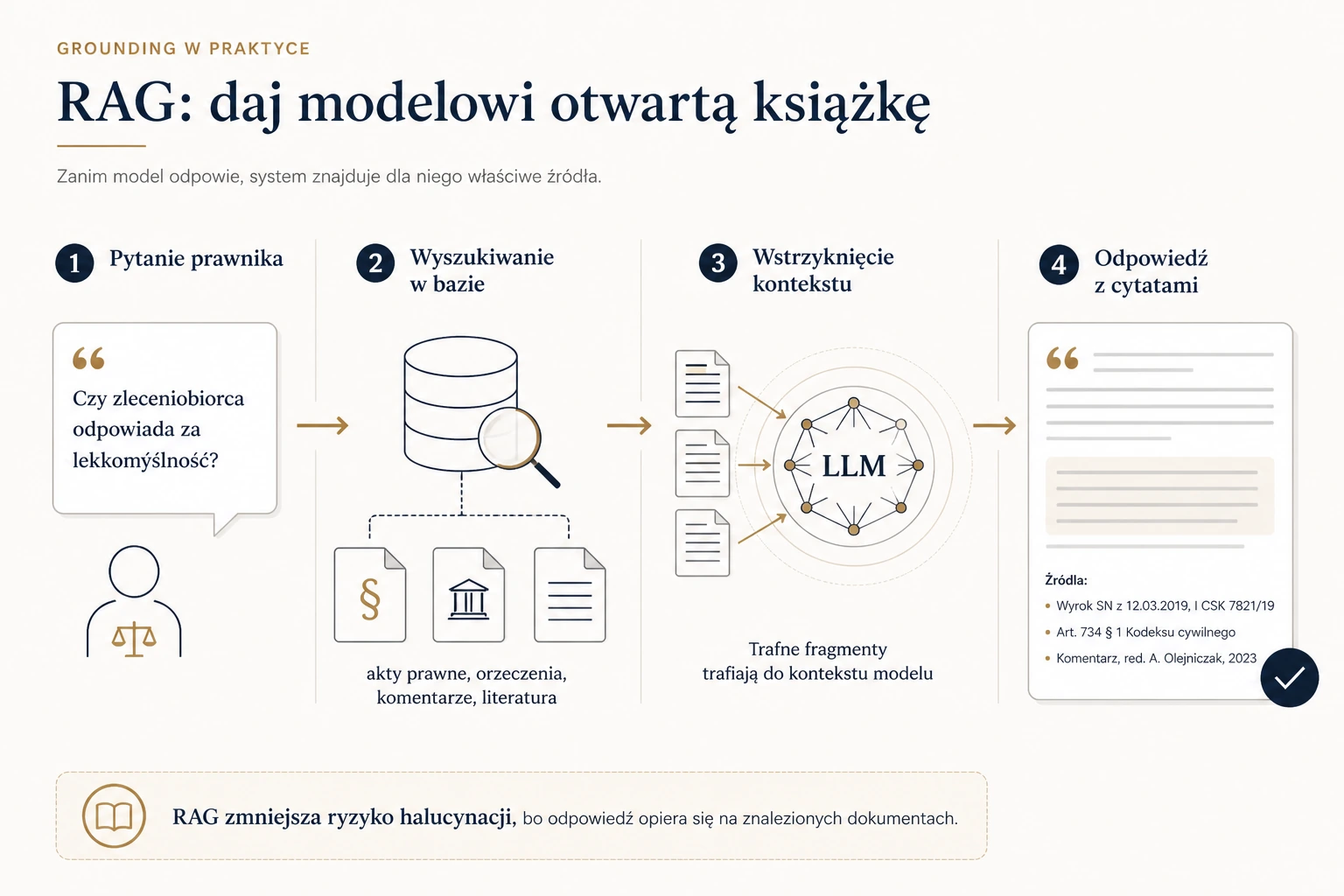
Najbardziej klasyczna odpowiedź to RAG — Retrieval-Augmented Generation, czyli generowanie wspomagane wyszukiwaniem.
Pomysł jest prosty: użytkownik zadaje pytanie, system najpierw wyszukuje trafne fragmenty prawdziwych dokumentów, dokleja je do kontekstu modelu, a dopiero potem prosi go o odpowiedź.
Można to porównać do studenta na egzaminie z otwartą książką. Bez książki polega na pamięci. Z książką — odpowiada na podstawie tego, co ma przed oczami.
RAG nie sprawia, że model staje się „mądrzejszy" w jakimś abstrakcyjnym sensie. Po prostu mocniej zakotwicza odpowiedź w źródłach.
Jak system znajduje trafne fragmenty?
Tu wchodzą do gry embeddingi, czyli osadzenia wektorowe. Każdy fragment tekstu — zdanie z orzeczenia, akapit komentarza, fragment przepisu — zostaje zamieniony na punkt w wielowymiarowej przestrzeni znaczeniowej. Treści podobne leżą blisko siebie, niepodobne — daleko.
Pytanie użytkownika trafia do tej samej przestrzeni. System nie szuka więc identycznych słów, tylko fragmentów najbliższych znaczeniowo. Dlatego zapytanie o „lekkomyślność zleceniobiorcy" potrafi wyciągnąć też treści o „winie nieumyślnej", „należytej staranności" czy „rażącym niedbalstwie".
Limity klasycznego RAG
RAG jest mocny, ale nie magiczny. Klasyczna wersja ma trzy ograniczenia: jedno wyszukiwanie na zapytanie, brak iteracji, ograniczony kontekst. A prawo rzadko da się sprowadzić do jednej kwerendy. Tu zaczynają się agenci.
Agenci AI — LLM, który potrafi działać
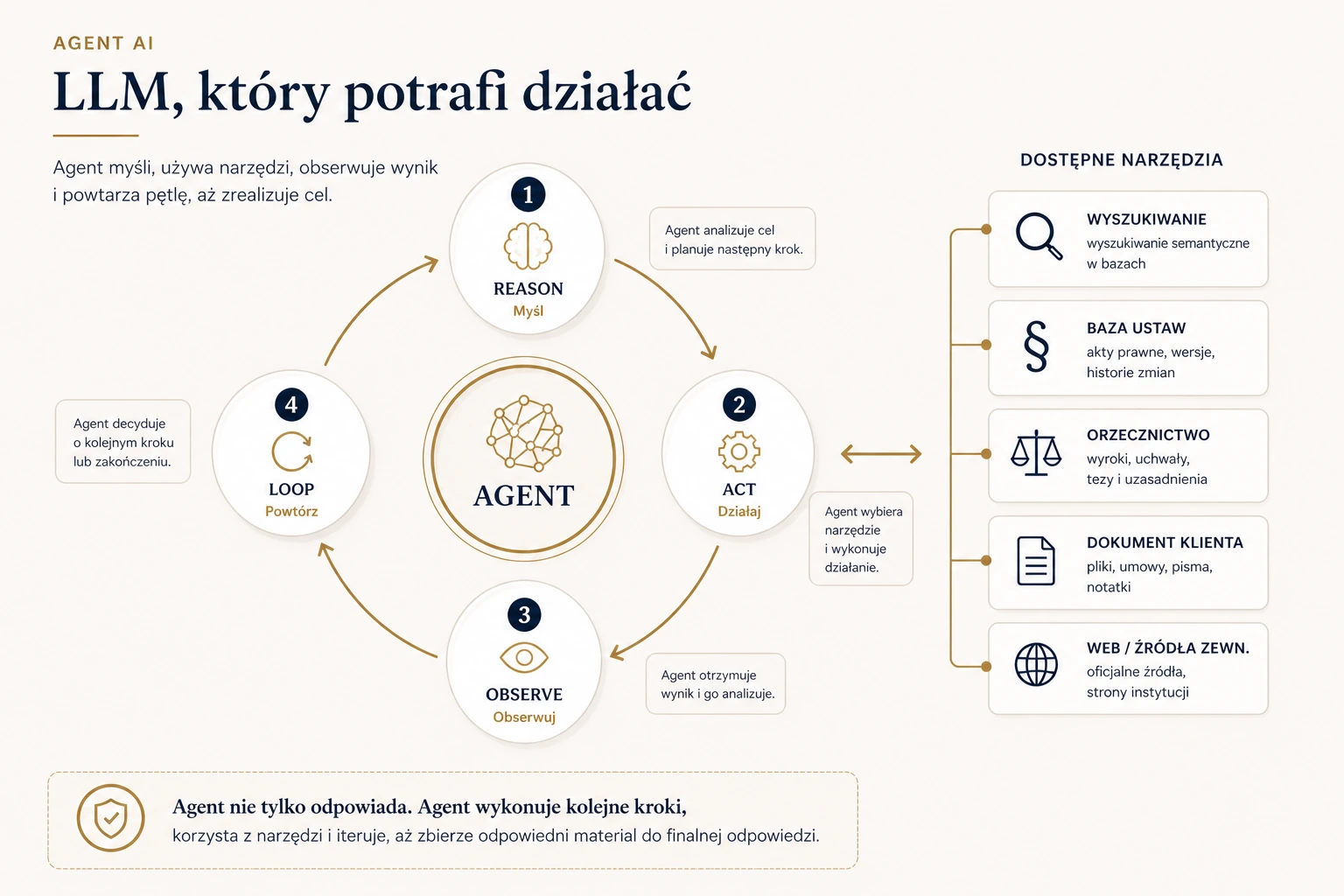
Klasyczny LLM działa tak: dostaje pytanie, generuje odpowiedź, kończy. Agent działa inaczej.
Agent to model językowy w pętli, z dostępem do narzędzi. Najpopularniejszy wzorzec takiego działania to ReAct — od Reason + Act.
Schemat jest prosty: model zastanawia się, co zrobić dalej, wybiera narzędzie, wykonuje działanie, ogląda wynik, wraca do myślenia i decyduje o kolejnym kroku. Tymi narzędziami może być wyszukiwanie orzecznictwa, sprawdzenie przepisu, otwarcie dokumentu klienta, porównanie dwóch źródeł albo weryfikacja cytatu. Dzięki temu agent jest dużo bliższy temu, jak naprawdę pracuje prawnik.
Przykład: agent przygotowuje memo
Załóżmy, że prosisz: „Przygotuj memo o granicach tajemnicy zawodowej radcy prawnego w postępowaniu karnym, ze szczególnym uwzględnieniem korespondencji elektronicznej z klientem".
Klasyczny czat napisze coś z głowy. Klasyczny RAG wykona jedno wyszukiwanie i odpowie na bazie znalezionych fragmentów. Agent zrobi więcej: rozłoży pytanie na wątki, znajdzie ramy ogólne, sprawdzi przepisy proceduralne, otworzy najważniejsze orzeczenia, zawęzi wyszukiwanie do nowszych spraw, zweryfikuje przepisy — i dopiero wtedy zacznie składać memo.
Agentic search — szukanie z głową
Skoro wiadomo już, czym jest agent, łatwo zrozumieć agentic search. To wyszukiwanie prowadzone przez agenta — nie człowieka i nie pojedynczy RAG, tylko system, który planuje strategię, wykonuje serię zapytań, zawęża i rozszerza zakres, sprawdza wyniki krzyżowo i dopiero potem syntetyzuje odpowiedź.
Klasyczny search: wpisujesz frazę, dostajesz listę wyników, klikasz, czytasz, poprawiasz frazę, powtarzasz. Klasyczny RAG: wpisujesz pytanie, system robi jedno wyszukiwanie semantyczne i odpowiada. Agentic search: wpisujesz pytanie, agent rozbija problem na aspekty, robi serię wyszukiwań pod różnymi kątami, sprawdza wyniki — i dopiero potem składa odpowiedź.

Lexedit pod maską — jak zbudowany jest poważny system
Teraz konkret. Pokażę poglądowo, jak wygląda architektura poważnego systemu prawniczego — na przykładzie Lexedita. Nie chodzi o to, że każdy taki system musi być zbudowany identycznie. Chodzi o wzorzec, który odróżnia narzędzie prawnicze od „ChatGPT dla prawników".
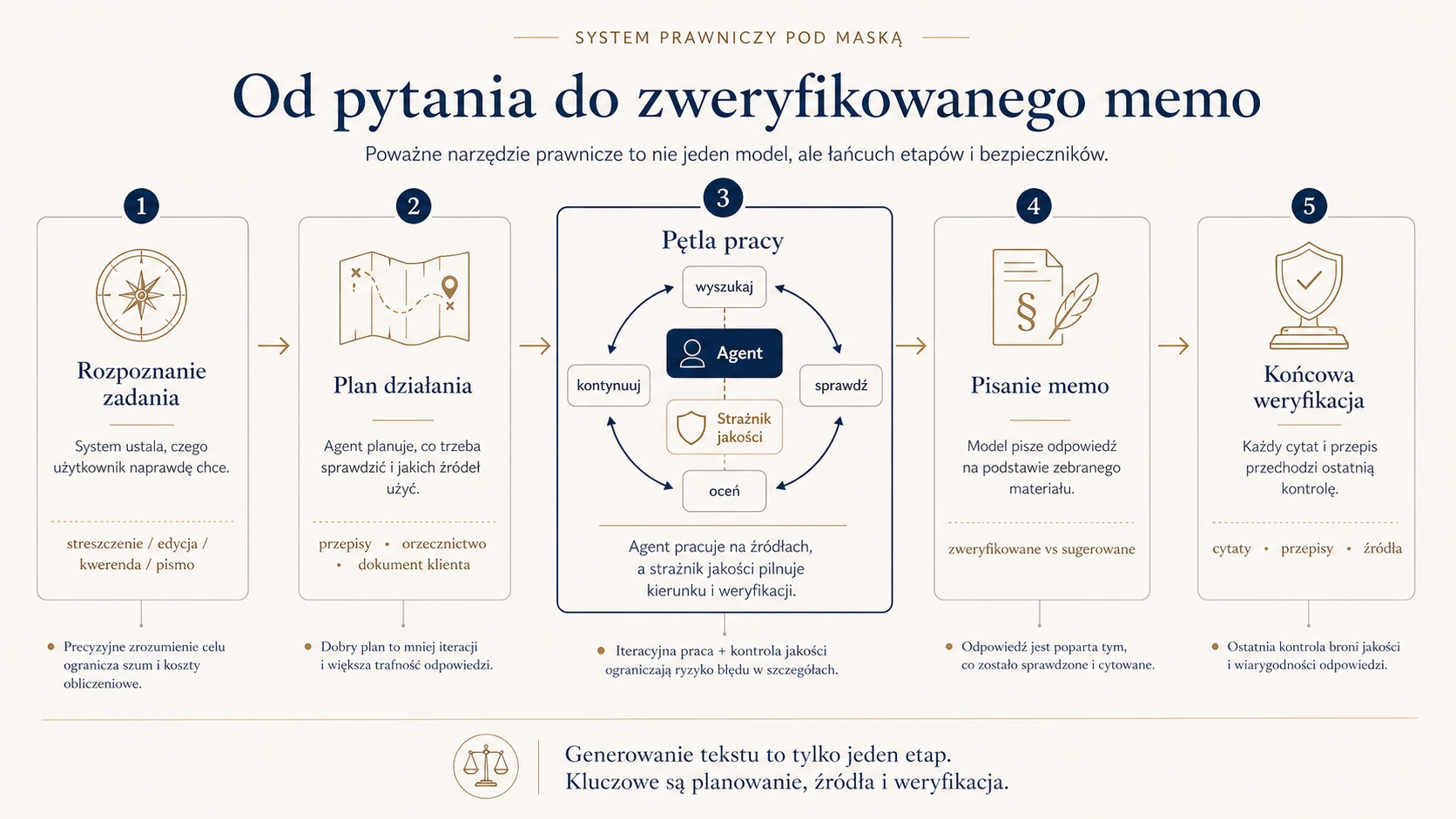
Najważniejsza obserwacja jest prosta: to nie jeden monolityczny model, który dostaje pytanie i wypluwa odpowiedź. To łańcuch etapów, w którym samo generowanie tekstu jest oddzielone od planowania, wyszukiwania, weryfikacji i kontroli jakości.
Najpierw: o co właściwie chodzi w pytaniu?
Nie każde pytanie prawnika to to samo zadanie. „Streść mi ten dokument" nie wymaga ani agenta, ani kwerendy. „Popraw stylistycznie ten paragraf" to edycja, nie research. „Znajdź orzecznictwo o przedawnieniu" to typowe wyszukiwanie. „Napisz pozew o zapłatę" to zadanie złożone, łączące kilka rzeczy naraz.
Dlatego dobry system zaczyna od rozpoznania, z jakim typem pracy ma do czynienia. Od tej decyzji zależy, jakie narzędzia w ogóle się włączą.
Potem: zaplanuj, zanim ruszysz
Dobry agent nie zaczyna od wyszukiwania. Najpierw planuje: jaka to dziedzina prawa, które przepisy będą kluczowe, jakie aspekty problemu trzeba sprawdzić i czego musi się dowiedzieć, żeby odpowiedź była kompletna.
Już na tym etapie da się ograniczyć ryzyko halucynacji. Jeżeli model planuje powołać się na przepis, który w danej ustawie nie istnieje, system może to wychwycić, zanim agent zbuduje na nim cokolwiek dalej.
Pętla weryfikacji — jak złapać najgroźniejszy typ błędu
Najgroźniejszy błąd to nie ten, w którym model zmyśla coś od zera, tylko ten, w którym powołuje się na źródło istniejące, ale niemówiące tego, co model zakłada.
Dlatego w poważnym systemie weryfikacja działa jak pętla: model proponuje przepis, system próbuje go odnaleźć w prawdziwej bazie, jeśli znajdzie — oddaje modelowi rzeczywistą treść, a model może swoją tezę potwierdzić, zmodyfikować albo wycofać.
To nie jest jednorazowe sprawdzenie typu „czy artykuł istnieje?". To konfrontacja z prawdą źródłową.
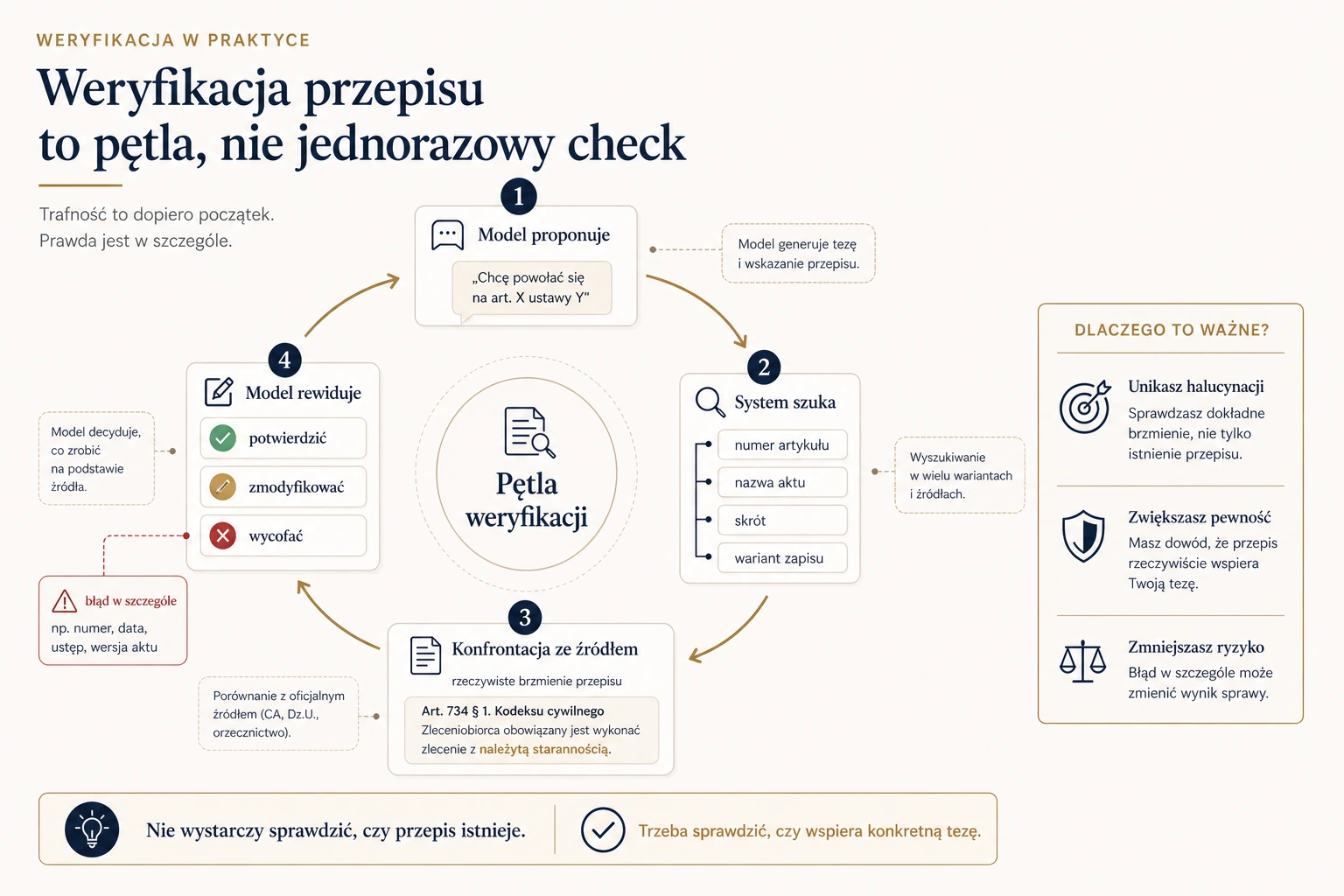
Pętla pracy — agent i strażnik jakości
W sercu systemu agent nie pracuje sam. Towarzyszy mu drugi mechanizm — strażnik jakości. Agent jest twórczy: kombinuje, próbuje różnych ścieżek, szuka. Strażnik jest restrykcyjny: pilnuje, czy agent nie powtarza tych samych ruchów, nie cytuje niezweryfikowanych źródeł, czy ma już dość materiału — albo, przeciwnie, czy nie kończy zbyt wcześnie.
Pisanie memo — z dyscypliną cytowań
Kiedy system uzna, że materiał jest gotowy, zaczyna pisać. Dobry system nie wrzuca wszystkiego do jednego worka. Oddziela to, co zweryfikowane — twarde źródła — od tego, co tylko sugerowane, czyli pomocnicze, ale nie w pełni potwierdzone. Końcowy dokument ma wtedy strukturę, która oddaje poziom pewności.
Sędzia po fakcie — końcowa weryfikacja cytatów
Nawet po napisaniu memo system może jeszcze raz przejść przez każdy cytat: czy sygnatura istnieje, czy cytat naprawdę pochodzi z tego źródła, czy przepis istnieje i czy jego treść zgadza się z tezą. Jeśli coś nie pasuje, system próbuje poprawić. A jeśli nie potrafi — oznacza problem otwarcie.
Zobacz, jak agent badawczy Lexedita prowadzi cytowanie pod kontrolą — od planu, przez weryfikację, po sędziego cytatów.
SprawdźSiedem zasad praktycznych
1. Zawsze wiedz, z czym pracujesz
Czat ogólny traktuj jak inteligentnego, oczytanego, ale niezweryfikowanego rozmówcę. Świetny do brainstormingu, redakcji, tłumaczenia pojęć i planowania struktury. Nie do ślepego cytowania sygnatur i przepisów.
2. Specjalistyczne narzędzie zawsze bije czat ogólny — w swojej dziedzinie
Jeśli masz pod ręką system z bazą źródeł i weryfikacją cytowań, używaj go do pracy prawniczej.
3. Daj jak najwięcej kontekstu
Dobry prompt prawniczy to często 5–10 zdań, nie 5 słów.
4. Iteruj
Pierwsza odpowiedź rzadko jest końcem pracy. Traktuj ją jak pierwszy szkic.
5. Zawsze wyrywkowo weryfikuj cytaty
Nawet dobre systemy potrafią się pomylić. Sprawdź 2–3 cytaty z każdego memo.
6. Audytuj kroki agenta
Jeśli narzędzie pokazuje Ci, co po kolei zrobiło, korzystaj z tego. To nie ozdobnik — to kontrola.
7. Bądź szczególnie sceptyczny wobec odpowiedzi, które brzmią idealnie
Najgroźniejsze halucynacje są eleganckie, uporządkowane i bardzo przekonujące.
Zakończenie: rozumienie jako przewaga
Wróćmy do opinii z otwarcia — tej świetnie napisanej, bez widocznych źródeł. Pomocna jako szkic, ale niemożliwa do złożenia bez sprawdzenia podstaw.
Z narzędziami AI w prawie jest tak samo. Różnica jest jedna: same narzędzia zmieniają się bardzo szybko, a stawką jest Twoja reputacja, klient i wynik sprawy. Im wcześniej wiesz, na czym opiera się odpowiedź, którą trzymasz przed sobą, tym mniejsze ryzyko, że okaże się to elegancko ubraną intuicją.
Po lekturze tego artykułu masz mapę, która przeżyje konkretne narzędzia. Nie chodzi o to, żebyś pamiętał, że Lexedit ma planner, router czy strażnika jakości. Chodzi o to, żebyś potrafił w pięć minut ocenić, czy coś jest gołym LLM-em, czy ma grounding, czy pracuje jak agent, czy weryfikuje cytaty, czy pokazuje źródła — i czy w ogóle można mu zaufać, a jeśli tak, to w jakim zakresie.
To jest właśnie ta przewaga, której wielu prawników jeszcze nie ma. I której przez najbliższe lata długo nie będą mieli.
Najczęstsze pytania
Czym jest LLM?
Large Language Model to system uczony przewidywania kolejnego tokenu w kontekście. Wytrenowany na ogromnych korpusach tekstu, generuje wypowiedzi statystycznie pasujące do wzorców z treningu — nie wyszukuje faktów w bazie, tylko produkuje najbardziej prawdopodobny dalszy ciąg tekstu.
Dlaczego AI halucynuje, czyli zmyśla wyroki i przepisy?
Bo LLM nie ma dostępu do źródła prawdy — przewiduje tokeny, które brzmią poprawnie. Halucynacja w prawie najczęściej dotyczy detali: sygnatury wyglądającej prawidłowo, daty zbliżonej do prawdziwej, przepisu który istnieje, ale nie mówi tego, co model twierdzi. Ryzyko ogranicza grounding w prawdziwych źródłach (RAG, agentic search) i weryfikacja cytatów.
Co to jest RAG (Retrieval-Augmented Generation)?
Architektura, w której system przed wygenerowaniem odpowiedzi wyszukuje trafne fragmenty prawdziwych dokumentów i wstrzykuje je do kontekstu modelu. Model nie zgaduje z pamięci — odpowiada na podstawie treści, którą widzi przed sobą. To kluczowa technika ograniczania halucynacji.
Czym agent AI różni się od ChatGPT?
Agent AI to LLM działający w pętli z dostępem do narzędzi: planuje, wykonuje wyszukiwania, sprawdza źródła, weryfikuje cytaty i decyduje o kolejnym kroku. ChatGPT w trybie czatu generuje jedną odpowiedź z pamięci treningowej. W pracy prawniczej agent jest dużo bliżej tego, jak naprawdę pracuje prawnik.
Czy AI dla prawników zastąpi prawnika?
W najbliższych latach — nie. AI z grounding-iem i weryfikacją cytatów jest narzędziem, które przyspiesza research, draft i analizę dokumentów. Decyzja, ocena ryzyka i odpowiedzialność zawodowa nadal leżą po stronie prawnika. Realna przewaga wynika ze świadomego korzystania z odpowiedniej klasy narzędzia, nie z jego wyboru zamiast kogoś.
Jak bezpiecznie używać ChatGPT w pracy prawnika?
Traktuj go jak inteligentnego, niezweryfikowanego rozmówcę: dobry do brainstormingu, redakcji, struktury, tłumaczenia pojęć. Nie do ślepego cytowania sygnatur, dat i przepisów. Jeśli powołujesz cytaty, zawsze weryfikuj 2–3 z każdego memo. Do pracy z orzecznictwem używaj specjalistycznego narzędzia z bazą źródeł i weryfikacją cytatów.
Glosariusz
- LLM (Large Language Model) — duży model językowy, trenowany do przewidywania kolejnych tokenów w kontekście.
- Token — jednostka tekstu, na której operuje model; bywa słowem, częścią słowa, liczbą albo pojedynczym znakiem.
- Halucynacja — treść wygenerowana przez model, która brzmi wiarygodnie, ale jest nieprawdziwa.
- Grounding — zakotwiczenie odpowiedzi w prawdziwych źródłach.
- RAG (Retrieval-Augmented Generation) — generowanie wspomagane wyszukiwaniem; model odpowiada na podstawie wcześniej znalezionych dokumentów.
- Embedding / wektor — matematyczna reprezentacja znaczenia fragmentu tekstu.
- Agent — LLM działający w pętli, z dostępem do narzędzi.
- ReAct — wzorzec działania agenta: myśl → działaj → obserwuj → powtórz.
- Agentic search — wyszukiwanie prowadzone przez agenta, a nie pojedyncze zapytanie.
- Weryfikacja cytatów — sprawdzenie, czy cytat naprawdę pochodzi ze wskazanego źródła i czy źródło rzeczywiście wspiera daną tezę.