How Legal AI Tools Really Work: A Lawyer's Guide
Imagine receiving a beautifully written legal opinion. The language is precise, the structure is logical, the conclusions sound persuasive. There is just one problem: you cannot see the sources. You do not know which statements come from a statute, which from case law, which from commentary, and which are simply the author's elegantly phrased intuition.
A draft like that can still be useful. It frames the problem, suggests a line of argument, and gets you started faster. But you would never send it to a client or file it in court without checking the foundations.
Legal AI tools are similar — except it is even easier to trust them too quickly. The text appears instantly, sounds professional, and is often genuinely close to the truth.
A lawyer who treats ChatGPT like a "smart search engine" will, sooner or later, cite a case that does not exist. A lawyer who does not understand the difference between a chat interface and an agent will miss the fact that someone else is doing in thirty minutes what used to take half a day. A lawyer who does not understand grounding cannot tell why one tool fails more often than another — or how to choose wisely.
This article will not turn you into an AI engineer. It is meant to give you a durable map: what an LLM is, why it can hallucinate, how ChatGPT differs from a specialized legal tool, what RAG is, what an AI agent does, how agentic search works — and how to use all of this sensibly in daily legal work.
What is an LLM?
An LLM — a large language model — is most simply described as a system trained to predict the next token in context.
That is a simplification, but a useful one. It explains two things at once: where the model's fluency comes from, and why fluency is not a guarantee of truth.
Imagine giving the model the start of a sentence:
"The Supreme Court, in its ruling of March 12, 2019, in case no. …"
The model does not "look the answer up" the way a search engine does. It analyzes everything it has seen so far in the conversation and, based on the patterns it learned during training, picks the next tokens — the ones that best fit as a continuation of that text.
The crucial point: it is not predicting a single word in isolation. A modern model uses broad context — the sentence, prior paragraphs, the question itself, the tone, the document type, the area of law, similar linguistic structures, and often the entire conversation up to that moment. That is what lets it sound like a lawyer, draft arguments, and produce memos that look professional at first glance.
But the fact that the model predicts what an answer should sound like is not the same as guaranteeing that every detail in that answer is true.

Tokens: small detail, big consequences
A model does not operate on "words" in the everyday sense. It operates on tokens — chunks of text that may be a whole word, part of a word, a number, or a single character.
This has very concrete consequences. To the model, numbers are not "numbers" in the arithmetic sense. A case citation, a date, or a statutory section number is just another sequence of tokens. The model knows their typical format, and can reproduce it, but it has no built-in guarantee that a particular reference matches a real source.
That is why AI tools are excellent for drafting, restructuring, summarizing, translation, and proposing argument structures. They demand much more caution wherever the answer involves citations, dates, exact quotations, reporter references, or specific statutory provisions.
Hallucinations — small risk, large consequences
In May 2023, New York attorney Steven Schwartz filed a court submission citing six cases. All six — complete with names, citations, dates, and excerpts — had been generated by ChatGPT. None of them existed. The court imposed sanctions, and Mata v. Avianca, Inc. became a global warning sign for the legal profession.
The simplest explanation is: "the model made up the cases." That is true, but too flat.
An LLM is not blindly guessing. It uses broad context: the question, the prior conversation, the area of law, the style of judicial writing, the structure of legal arguments, citation patterns, and semantic relationships between concepts. Given good context, it often lands very close to the correct answer.
That is precisely why models are useful. The problem is subtler: context improves accuracy, but it does not replace the source.
A model can correctly recognize that a question is about contract law. It can spot that the issue is contractual liability, due care, or the limitation period. It can even put together a credible chain of reasoning. But the moment it descends to a precise detail — a citation, a date, a statutory section, the attribution of a particular proposition to a particular case — the risk shows up.
Usually small. In law, almost always critical.
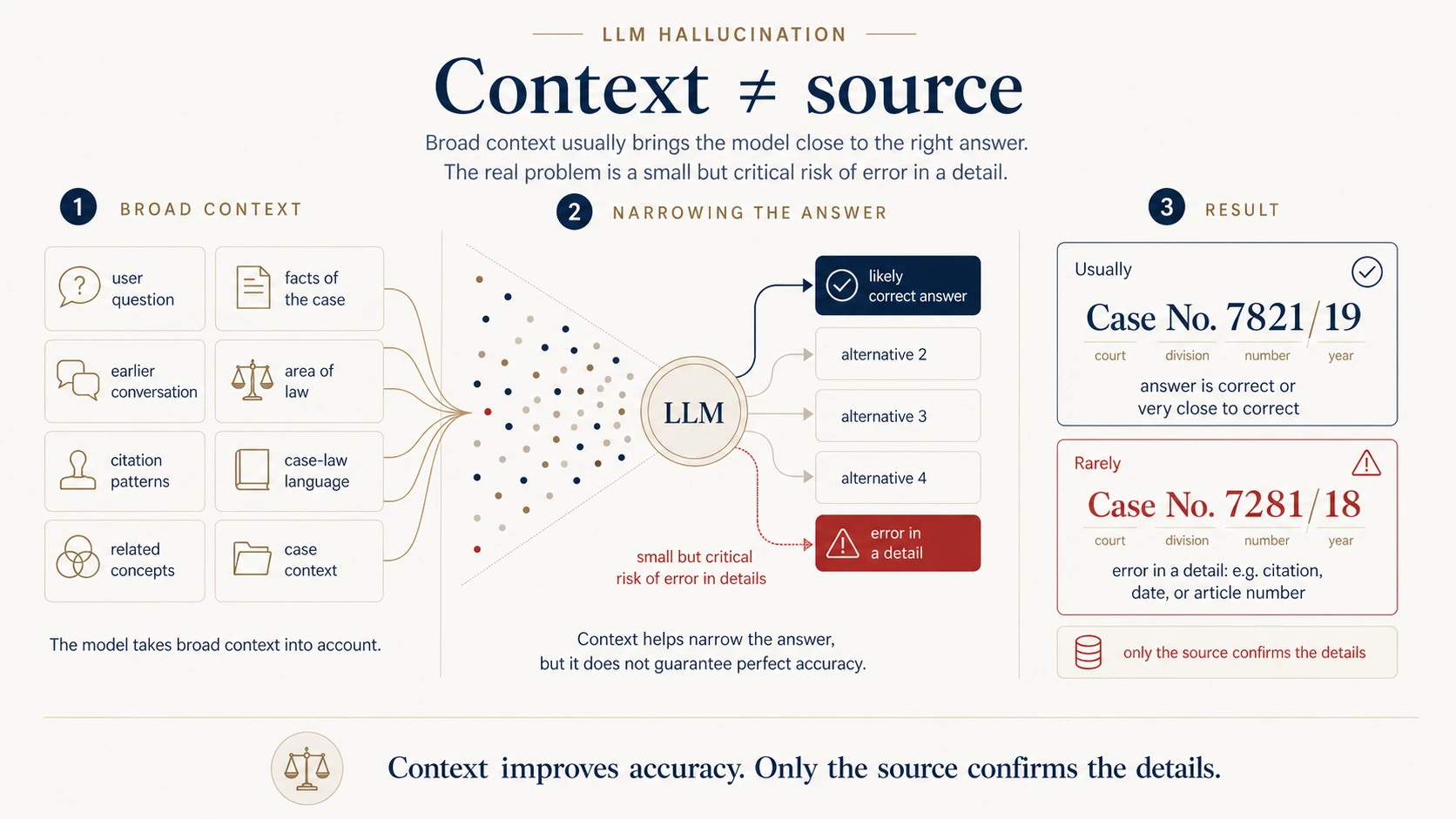
For a reader, the difference between "The Supreme Court has spoken on similar matters" and "The Supreme Court, in its ruling of March 12, 2019, I CSK 7821/19, held that…" is fundamental. The first is a generic claim. The second pretends to be a verifiable fact.
A hallucination rarely looks absurd
In legal work, a hallucination almost never looks like nonsense. It looks like an answer that recognizes the problem, sounds right, has a logical structure, uses the proper legal register, and is wrong in one precise detail.
The model may hand you a citation that is one digit off, attribute a correct proposition to the wrong case, fuse fragments of several similar cases into one that does not exist, or cite a real provision that does not actually say what the model assumes.
Two types of hallucination
Type one: the model cites something that does not exist — a fictional case, citation, or statutory reference. This kind of error is relatively easy to catch by pulling the source.
Type two: the model cites something that does exist, but misstates its meaning. The case exists. The provision exists. The date looks right. The source simply does not support the proposition.
The second type is more dangerous because it is easier to miss. The right question is not only "does this source exist?" but also "does this source actually say what the model claims?"
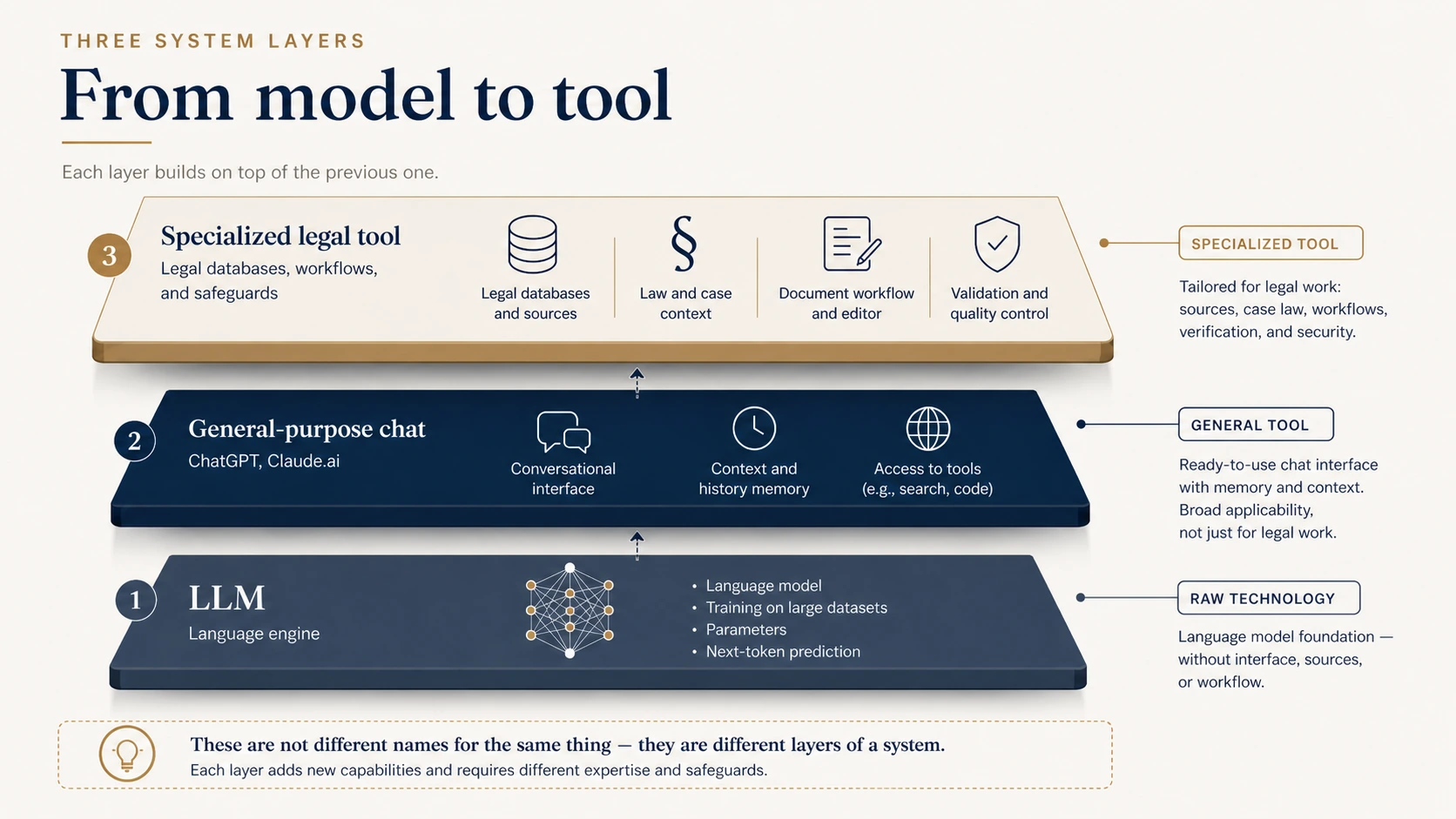
LLM, general chat and a legal application — they are not synonyms
This is where many people mix concepts. A lawyer says, "I used AI." But what does that actually mean? A raw language model? A general chat interface like ChatGPT? A specialized legal tool? An internal firm system tied to its document base?
These are not the same. The most honest framing is to think of them as three layers of one stack.
At the bottom sits the LLM itself — the underlying technology. A trained model that predicts the next tokens, and nothing more.
Above it are general-purpose applications like ChatGPT. They add a conversation interface, context, session memory, sometimes internet access — but inside they still run on a general model, without a domain-specific source database.
At the top sit legal tools, which add another layer on top: case-law databases, statute databases, statute versioning, citation validation, integration with firm documents, drafting and memo workflows, quality control.
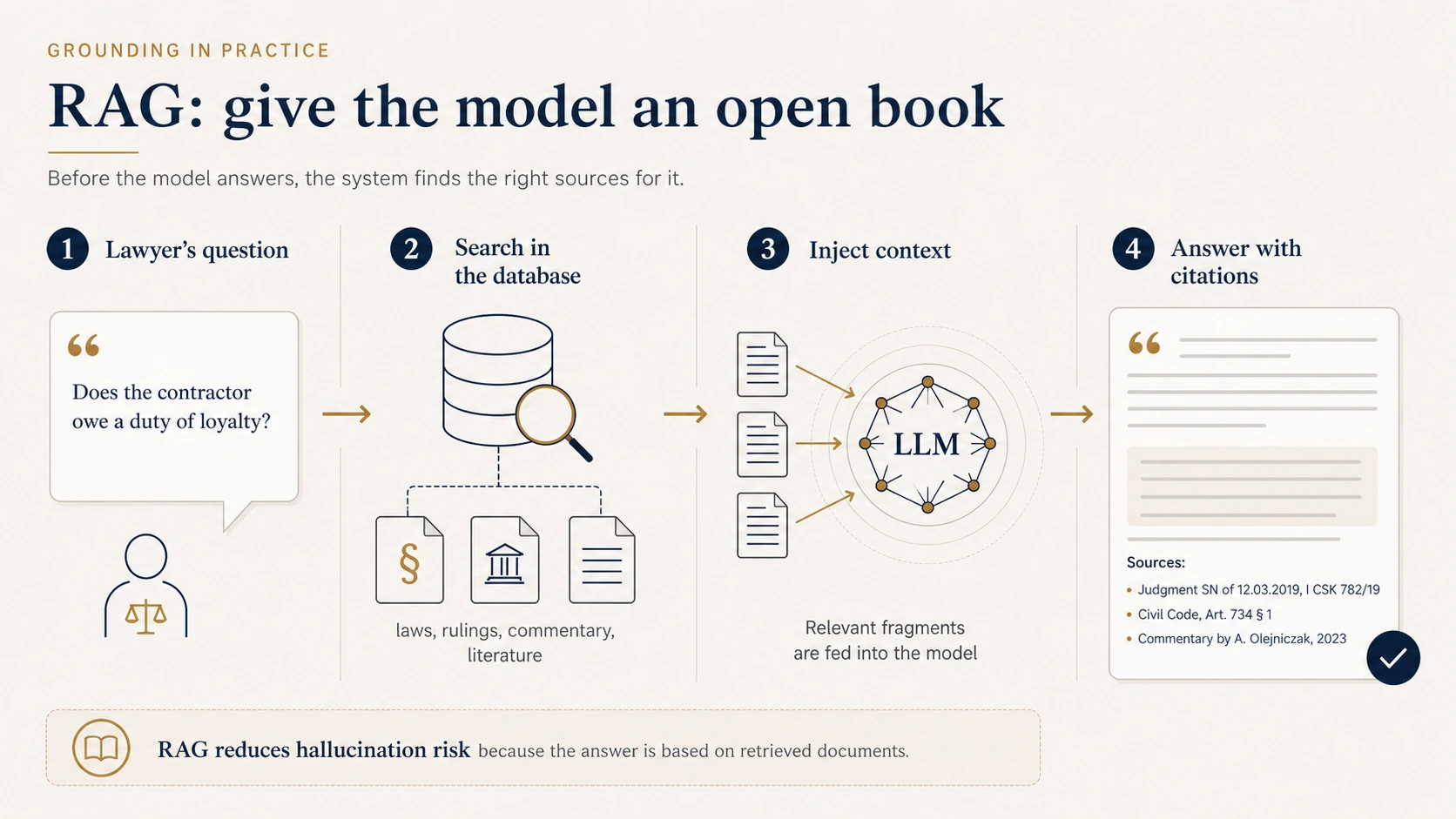
RAG — give the model an open book
We have established that without access to sources, a model produces persuasive text that is not necessarily verified. How do we reduce that risk?
The classic answer is RAG — retrieval-augmented generation.
The idea is simple: the user asks a question, the system first retrieves relevant fragments from real documents, attaches them to the model's context, and only then asks the model to answer.
Think of a student taking an exam with the book open. Without the book, they rely on memory. With the book, they answer based on what is right in front of them.
RAG does not make the model "smarter" in any abstract sense. It anchors the answer in real sources.
How does the system find the right fragments?
This is where embeddings come in. Imagine each text fragment — a sentence from a judgment, a paragraph from a treatise, a statutory provision — placed as a point in a high-dimensional semantic space. Similar texts cluster together; unrelated texts are far apart.
The user's question lands in the same space. So the system is not looking for identical words; it is looking for the fragments that are nearest in meaning. A query about "negligence by a contractor" can therefore surface material on "lack of due care," "gross negligence," and related concepts — even when the wording differs.
The limits of classic RAG
RAG is powerful, but not magic. Classic RAG has three shortcomings: a single retrieval step, no iteration, and a fixed-size context window. Real legal problems rarely fit one query. That is where agents come in.
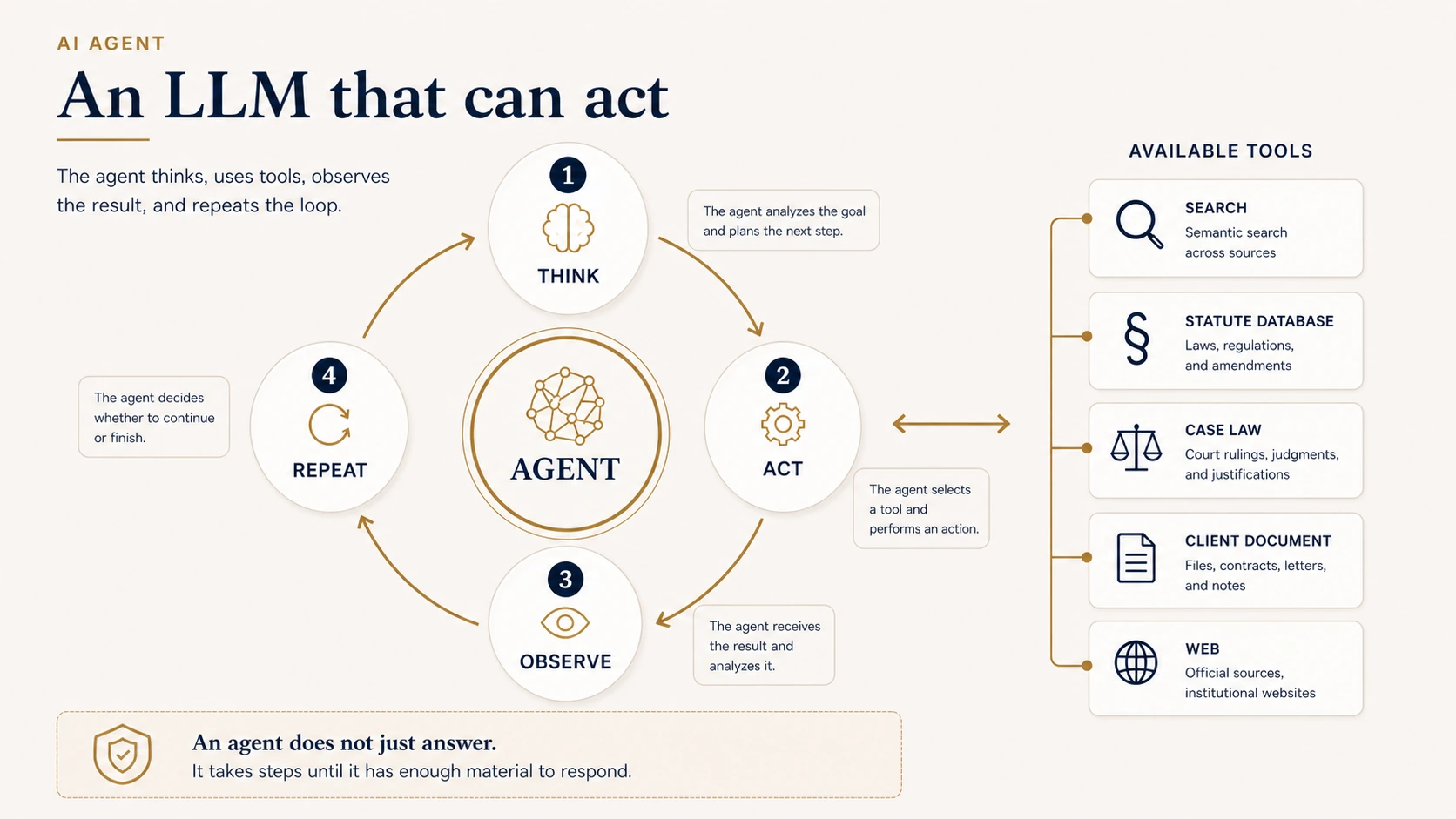
AI agents — an LLM that can act
A classic LLM takes a question, generates an answer, and stops. An agent works differently.
An agent is a language model running in a loop with access to tools. The most common pattern is ReAct — Reason + Act.
The pattern is straightforward: the model thinks about what to do next, picks a tool, runs an action, observes the result, then thinks again and decides on the next step. Tools can be a case-law search, a statute lookup, opening a client document, comparing two sources, or verifying a citation. That puts an agent much closer to the way a lawyer actually works.
Example: an agent prepares a memo
Suppose you ask: "Prepare a memo on the limits of attorney-client privilege in criminal proceedings, with a focus on electronic correspondence."
A general chat will write something from memory. A classic RAG system will run one retrieval and answer based on the fragments it pulls. An agent does more: it breaks the question into sub-issues, retrieves the general framework, checks procedural rules, opens the leading cases, narrows the search to recent decisions, verifies the statutes — and only then drafts the memo.
Agentic search — searching with a plan
Once you understand agents, agentic search follows naturally. It is search performed by an agent — not a human, not a single RAG call, but a system that plans a strategy, runs a series of queries, narrows and broadens the scope, cross-checks results, and only then synthesizes an answer.
Classic search: you type a query, scan a list of results, click, read, refine, repeat. Classic RAG: you ask a question, the system runs one semantic search and answers. Agentic search: you ask a question, the agent breaks the problem into aspects, runs several searches from different angles, checks the results — and then writes the answer.
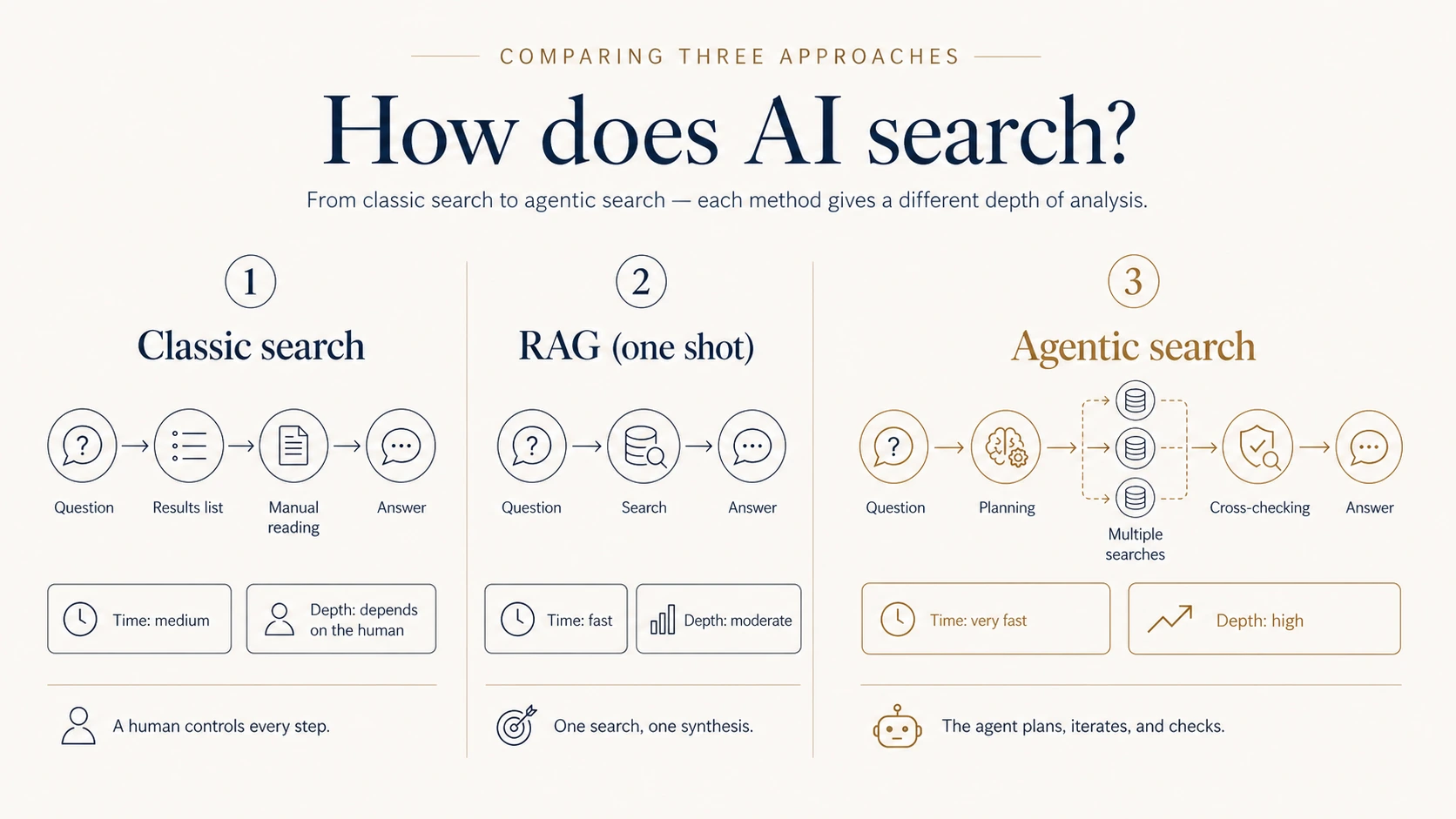
Lexedit under the hood — what a serious system looks like
Now for the concrete part. I'll walk through the architecture of a serious legal AI system using Lexedit as an example. The point is not that every system has to be built identically — it is the pattern that distinguishes a real legal tool from "ChatGPT for lawyers."
The single most important observation is that this is not one monolithic model that gets a question and returns an answer. It is a chain of stages, where text generation is decoupled from planning, retrieval, verification, and quality control.
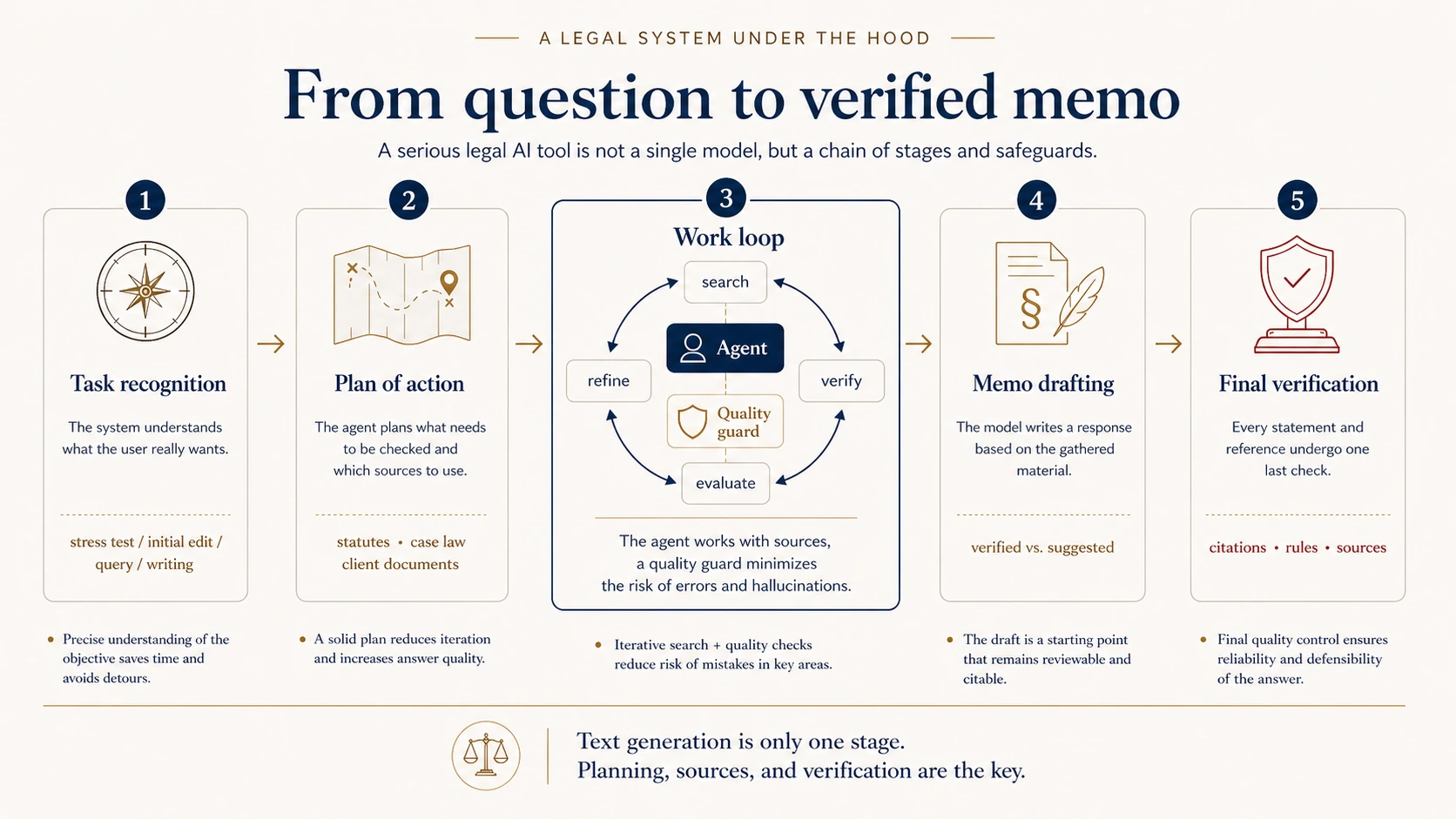
First: what are you actually trying to do?
Not every legal request is the same task. "Summarize this document" needs neither agent nor query. "Improve the style of this paragraph" is editing, not research. "Find case law on limitation periods" is a research task. "Draft a complaint" is a composite job that pulls several pieces together.
A good system starts by recognizing what kind of work it is being asked to do. That decision determines which tools fire at all.
Then: plan before you act
A good agent does not start with retrieval. It plans first: which area of law is this, which provisions are likely to matter, what aspects need to be checked, and what does it need before the answer can be considered complete.
You can already cut hallucination risk at this stage. If the model intends to cite a provision that does not exist in a given act, the system can flag that before the agent builds anything on top of it.
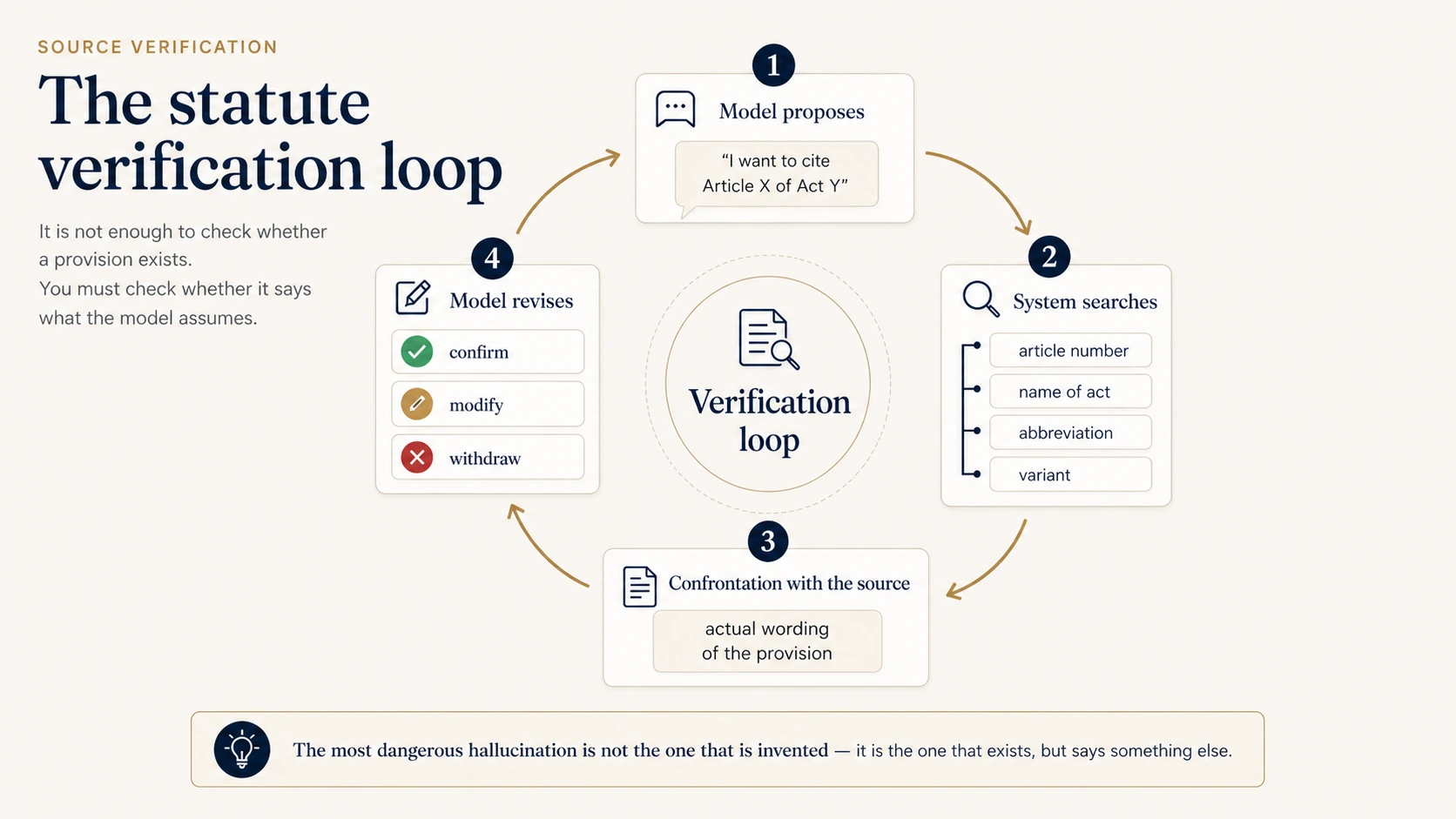
A verification loop — catching the most dangerous error
The most dangerous error is not the one where the model fabricates something out of thin air. It is the one where the model relies on a real source that does not actually say what the model claims.
That is why, in a serious system, verification looks like a loop: the model proposes a provision, the system tries to locate it in a real database, returns the actual text if it finds it, and the model can then confirm, modify, or withdraw its claim.
This is not a one-shot "does this article exist?" check. It is a confrontation with the source.
A working loop — agent plus quality guard
At the heart of the system, the agent does not work alone. It is paired with a quality guard. The agent is creative — combining moves, exploring routes, searching. The guard is restrictive — watching for repeated steps, unverified citations, premature stopping, or the opposite, overshooting after enough material has been collected.
Drafting the memo — with citation discipline
When the system decides the material is ready, it starts to write. A good system does not throw everything into one bucket. It separates verified material — hard sources — from suggested material that is helpful but not fully confirmed. The final document is structured to reflect that level of confidence.
A judge after the fact — final citation verification
Even after the memo is written, the system can walk through every citation again: does the case exist, does the quoted text actually come from that source, does the cited provision exist, and does its wording support the claim? If something is off, the system tries to fix it. If it cannot, it flags the issue rather than hiding it.
See how Lexedit's research agent runs every citation through plan → verification → final judge.
SprawdźSeven practical principles
1. Always know what you are working with
Treat a general chat like an intelligent, well-read, but unverified colleague. Useful for brainstorming, structure, drafting, and translation. Not for blindly citing case names, dates, or statutes.
2. A specialized tool always beats a general chat — in its own domain
If you have a system with a real source database and citation verification, use it for the legal work.
3. Give the system as much context as you can
A good legal prompt is often five to ten sentences, not five words.
4. Iterate
The first answer is rarely the end of the work. Treat it as a first draft.
5. Always spot-check citations
Even good systems can miss. Check two or three citations in every memo.
6. Audit the agent's steps
If the tool shows you what it did, use that information. It is not decoration — it is control.
7. Be most skeptical when the answer sounds perfect
The most dangerous hallucinations are elegant, orderly, and very persuasive.
Conclusion: understanding as an advantage
Come back to the opinion from the opening — the beautifully written one with no visible sources. Helpful as a draft, but not something you would file without checking the foundations.
Legal AI is the same. The only twist: the tools themselves change very fast, and the stakes are your reputation, your client, and the outcome of a case. The sooner you can tell what an answer is actually built on, the smaller the chance that it turns out to be elegantly phrased intuition.
After this article, you have a map that will outlive any specific tool. The point is not to remember that Lexedit has a planner, a router, or a quality guard. The point is to be able to look at a new tool in five minutes and decide: is this a raw LLM, does it have grounding, does it act like an agent, does it verify citations, does it show sources — and how far can it actually be trusted?
That is an edge most lawyers do not yet have. And, for a few years yet, most still won't.
Frequently asked questions
What is an LLM?
A large language model is a system trained to predict the next token in context. It is trained on vast text corpora and produces output that statistically fits the patterns it learned — it does not look facts up in a database, it generates the most likely continuation of the text.
Why does AI hallucinate cases and statutes?
Because an LLM has no access to a source of truth — it predicts tokens that sound right. In legal work, hallucinations most often hit the details: a citation that looks plausible, a date close to the real one, a real provision that does not actually say what the model claims. The risk is reduced by grounding (RAG, agentic search) and citation verification.
What is RAG (retrieval-augmented generation)?
An architecture in which the system first retrieves relevant fragments from real documents and injects them into the model's context before asking it to answer. The model is no longer guessing from training memory — it answers based on text it has in front of it. RAG is the core technique for reducing hallucinations.
How is an AI agent different from ChatGPT?
An AI agent is an LLM running in a loop with access to tools: it plans, runs searches, opens documents, verifies citations, and decides on the next step. ChatGPT in chat mode produces a single answer from training memory. For legal research, an agent is much closer to the way a lawyer actually works.
Will legal AI replace lawyers?
Not in the foreseeable future. Grounded AI with citation verification is a tool that speeds up research, drafting, and document analysis. Judgment, risk assessment, and professional responsibility remain with the lawyer. The real edge comes from knowing which class of tool to reach for, not from outsourcing the work.
How can lawyers safely use ChatGPT?
Treat it as an intelligent but unverified colleague: useful for brainstorming, structure, drafting, and translation; not for blindly citing case names, dates, or statutes. Always spot-check 2–3 citations in any memo. For real research, use a specialized tool with a source database and citation verification.
Glossary
- LLM (Large Language Model) — a model trained to predict the next token in context.
- Token — a unit of text the model operates on; can be a whole word, part of a word, a number, or a single character.
- Hallucination — output that sounds plausible but is not true.
- Grounding — anchoring the answer in real sources.
- RAG (Retrieval-Augmented Generation) — generation supported by retrieval; the model answers based on documents found in advance.
- Embedding / vector — a mathematical representation of the meaning of a text fragment.
- Agent — an LLM running in a loop with access to tools.
- ReAct — an agent pattern: think → act → observe → repeat.
- Agentic search — search driven by an agent rather than a single query.
- Citation verification — checking that a cited source exists and that it actually supports the proposition for which it is cited.